Difference between revisions of "The individual approach"
m |
m (→Selecting the error model) |
||
| (78 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
| − | + | ||
== Overview == | == Overview == | ||
| − | Before we start looking at modeling a whole population at the same time, we are going to consider only one individual from that population. Much of the basic methodology for modeling one individual follows through to population modeling. We will see that when stepping up from one individual to a population, the difference is that some parameters shared by individuals are considered to be drawn from a probability distribution. | + | Before we start looking at modeling a whole population at the same time, we are going to consider only one individual from that population. Much of the basic methodology for modeling one individual follows through to population modeling. We will see that when stepping up from one individual to a population, the difference is that some parameters shared by individuals are considered to be drawn from a [http://en.wikipedia.org/wiki/Probability_distribution probability distribution]. |
Let us begin with a simple example. | Let us begin with a simple example. | ||
| Line 8: | Line 8: | ||
concentration of a marker in the bloodstream is measured and plotted against time: | concentration of a marker in the bloodstream is measured and plotted against time: | ||
| − | ::[[File:New_Individual1.png]] | + | ::[[File:New_Individual1.png|link=]] |
We aim to find a mathematical model to describe what we see in the figure. The eventual goal is then to extend this approach to the ''simultaneous modeling'' of a whole population. | We aim to find a mathematical model to describe what we see in the figure. The eventual goal is then to extend this approach to the ''simultaneous modeling'' of a whole population. | ||
| Line 21: | Line 21: | ||
In our example, the concentration is a ''continuous'' variable, so we will try to use continuous functions to model it. | In our example, the concentration is a ''continuous'' variable, so we will try to use continuous functions to model it. | ||
| − | Different types of data (e.g., count data, categorical data, time-to-event data, etc.) require different types of models. All of these data types will be considered in due time, but for now let us concentrate on a continuous data model. | + | Different types of data (e.g., [http://en.wikipedia.org/wiki/Count_data count data], [http://en.wikipedia.org/wiki/Categorical_data categorical data], [http://en.wikipedia.org/wiki/Survival_analysis time-to-event data], etc.) require different types of models. All of these data types will be considered in due time, but for now let us concentrate on a continuous data model. |
A model for continuous data can be represented mathematically as follows: | A model for continuous data can be represented mathematically as follows: | ||
| Line 38: | Line 38: | ||
* $\psi=(\psi_1, \psi_2, \ldots, \psi_d)$ is a vector of $d$ parameters that influences the value of $f$. | * $\psi=(\psi_1, \psi_2, \ldots, \psi_d)$ is a vector of $d$ parameters that influences the value of $f$. | ||
| − | * $(e_1, e_2, \ldots, e_n)$ are called the ''residual errors''. Usually, we suppose that they come from some centered probability distribution: $\esp{e_j} =0$ | + | * $(e_1, e_2, \ldots, e_n)$ are called the ''residual errors''. Usually, we suppose that they come from some centered probability distribution: $\esp{e_j} =0$. |
| Line 70: | Line 70: | ||
| − | * ''Proportional error model'': $g=b\,f$. That is, $y_j=f_j+bf_j\teps_j$. This is for when we think the magnitude of the error is proportional to the value of the predicted value $f$. | + | * ''Proportional error model'': $g=b\,f$. That is, $y_j=f_j+bf_j\teps_j$. This is for when we think the magnitude of the error is proportional to the value of the predicted value $f$. |
| Line 104: | Line 104: | ||
=== Selecting structural and residual error models === | === Selecting structural and residual error models === | ||
| − | As we are interested in parametric modeling, we must choose parametric structural and residual error models. In the absence of biological (or other) information, we might suggest possible structural models just by looking at the graphs of time-evolution of the data. For example, if $y_j$ is increasing with time, we might suggest an affine, quadratic or logarithmic model, depending on the approximate trend of the data. If $y_j$ is instead decreasing ever slower to zero, an exponential model might be appropriate. | + | As we are interested in [http://en.wikipedia.org/wiki/Parametric_model parametric modeling], we must choose parametric structural and residual error models. In the absence of biological (or other) information, we might suggest possible structural models just by looking at the graphs of time-evolution of the data. For example, if $y_j$ is increasing with time, we might suggest an affine, quadratic or logarithmic model, depending on the approximate trend of the data. If $y_j$ is instead decreasing ever slower to zero, an exponential model might be appropriate. |
| − | However, often we have biological (or other) information to help us make our choice. For instance, if we have a system of differential equations describing how the drug is eliminated from the body, its solution may provide the formula (i.e., structural model) we are looking for. | + | However, often we have biological (or other) information to help us make our choice. For instance, if we have a system of [http://en.wikipedia.org/wiki/Differential_equation differential equations] describing how the drug is eliminated from the body, its solution may provide the formula (i.e., structural model) we are looking for. |
As for the residual error model, if it is not immediately obvious which one to choose, several can be tested in conjunction with one or several possible structural models. After parameter estimation, each structural and residual error model pair can be assessed, compared against the others, and/or validated in various ways. | As for the residual error model, if it is not immediately obvious which one to choose, several can be tested in conjunction with one or several possible structural models. After parameter estimation, each structural and residual error model pair can be assessed, compared against the others, and/or validated in various ways. | ||
| Line 117: | Line 117: | ||
| − | Given the observed data and the choice of a parametric model to describe it, our goal becomes to find the "best" parameters for the model. A traditional framework to solve this kind of problem is called | + | Given the observed data and the choice of a parametric model to describe it, our goal becomes to find the "best" parameters for the model. A traditional framework to solve this kind of problem is called [http://en.wikipedia.org/wiki/Maximum_likelihood maximum likelihood estimation] or MLE, in which the "most likely" parameters are found, given the data that was observed. |
The likelihood $L$ is a function defined as: | The likelihood $L$ is a function defined as: | ||
| Line 124: | Line 124: | ||
|equation=<math> L(\psi ; y_1,y_2,\ldots,y_n) \ \ \eqdef \ \ \py( y_1,y_2,\ldots,y_n; \psi) , </math> }} | |equation=<math> L(\psi ; y_1,y_2,\ldots,y_n) \ \ \eqdef \ \ \py( y_1,y_2,\ldots,y_n; \psi) , </math> }} | ||
| − | i.e., the conditional joint density function of $(y_j)$ given the parameters $\psi$, but looked at as if the data are known and the parameters not. The $\hat{\psi}$ which maximizes $L$ is known as the ''maximum likelihood estimator''. | + | i.e., the conditional [http://en.wikipedia.org/wiki/Joint_probability_distribution joint density function] of $(y_j)$ given the parameters $\psi$, but looked at as if the data are known and the parameters not. The $\hat{\psi}$ which maximizes $L$ is known as the ''maximum likelihood estimator''. |
Suppose that we have chosen a structural model $f$ and residual error model $g$. If we assume for instance that $ \teps_j \sim_{i.i.d} {\cal N}(0,1)$, then the $y_j$ are independent of each other and [[#cont|(1)]] means that: | Suppose that we have chosen a structural model $f$ and residual error model $g$. If we assume for instance that $ \teps_j \sim_{i.i.d} {\cal N}(0,1)$, then the $y_j$ are independent of each other and [[#cont|(1)]] means that: | ||
| Line 150: | Line 150: | ||
| − | This minimization problem does not usually have an analytical solution for nonlinear models, so an optimization procedure needs to be used. | + | This minimization problem does not usually have an [http://en.wikipedia.org/wiki/Analytical_expression analytical solution] for nonlinear models, so an [http://en.wikipedia.org/wiki/Mathematical_optimization optimization] procedure needs to be used. |
| − | However, for a few specific models, | + | However, for a few specific models, analytical solutions do exist. |
For instance, suppose we have a constant error model: $y_{j} = f(t_j ; \psi) + a \, \teps_j,\,\, 1\leq j \leq n,$ that is: $g(t_j;\psi) = a$. In practice, $f$ is not itself a function of $a$, so we can write $\psi = (\phi,a)$ and therefore: $y_{j} = f(t_j ; \phi) + a \, \teps_j.$ Thus, [[#LLL|(2)]] simplifies to: | For instance, suppose we have a constant error model: $y_{j} = f(t_j ; \psi) + a \, \teps_j,\,\, 1\leq j \leq n,$ that is: $g(t_j;\psi) = a$. In practice, $f$ is not itself a function of $a$, so we can write $\psi = (\phi,a)$ and therefore: $y_{j} = f(t_j ; \phi) + a \, \teps_j.$ Thus, [[#LLL|(2)]] simplifies to: | ||
| Line 168: | Line 168: | ||
\end{eqnarray} </math> }} | \end{eqnarray} </math> }} | ||
| − | where $\hat{a}^2$ is found by setting the partial derivative of $-2LL$ to zero. | + | where $\hat{a}^2$ is found by setting the [http://en.wikipedia.org/wiki/Partial_derivative partial derivative] of $-2LL$ to zero. |
Whether this has an analytical solution or not depends on the form of $f$. For example, if $f(t_j;\phi)$ is just a linear function of the components of the vector $\phi$, we can represent it as a matrix $F$ whose $j$th row gives the coefficients at time $t_j$. Therefore, we have the matrix equation $y = F \phi + a \teps$. | Whether this has an analytical solution or not depends on the form of $f$. For example, if $f(t_j;\phi)$ is just a linear function of the components of the vector $\phi$, we can represent it as a matrix $F$ whose $j$th row gives the coefficients at time $t_j$. Therefore, we have the matrix equation $y = F \phi + a \teps$. | ||
| Line 185: | Line 185: | ||
===Computing the Fisher information matrix=== | ===Computing the Fisher information matrix=== | ||
| − | The Fisher information is a way of measuring the amount of information that an observable random variable carries about an unknown parameter upon which its probability distribution depends. | + | The [http://en.wikipedia.org/wiki/Fisher_information Fisher information] is a way of measuring the amount of information that an observable random variable carries about an unknown parameter upon which its probability distribution depends. |
Let $\psis $ be the true unknown value of $\psi$, and let $\hatpsi$ be the maximum likelihood estimate of $\psi$. If the observed likelihood function is sufficiently smooth, asymptotic theory for maximum-likelihood estimation holds and | Let $\psis $ be the true unknown value of $\psi$, and let $\hatpsi$ be the maximum likelihood estimate of $\psi$. If the observed likelihood function is sufficiently smooth, asymptotic theory for maximum-likelihood estimation holds and | ||
| Line 195: | Line 195: | ||
|reference=(3) }} | |reference=(3) }} | ||
| − | where $I_n(\psis)$ is (minus) the Hessian (i.e. the matrix of the second derivatives) of the log-likelihood: | + | where $I_n(\psis)$ is (minus) the Hessian (i.e., the matrix of the second derivatives) of the log-likelihood: |
{{Equation1 | {{Equation1 | ||
| Line 220: | Line 220: | ||
|equation=<math>\widehat{\rm Var}(\hatpsi_k) = C_{kk}(\hatpsi) .</math> }} | |equation=<math>\widehat{\rm Var}(\hatpsi_k) = C_{kk}(\hatpsi) .</math> }} | ||
| − | We can thus derive an estimator of its standard error: | + | We can thus derive an estimator of its [http://en.wikipedia.org/wiki/Standard_error standard error]: |
{{Equation1 | {{Equation1 | ||
|equation=<math>\widehat{\rm s.e.}(\hatpsi_k) = \sqrt{C_{kk}(\hatpsi)} ,</math> }} | |equation=<math>\widehat{\rm s.e.}(\hatpsi_k) = \sqrt{C_{kk}(\hatpsi)} ,</math> }} | ||
| − | and a confidence interval of level $1-\alpha$ for $\psi_k^\star$: | + | and a [http://en.wikipedia.org/wiki/Confidence_interval confidence interval] of level $1-\alpha$ for $\psi_k^\star$: |
{{Equation1 | {{Equation1 | ||
|equation=<math>{\rm CI}(\psi_k^\star) = \left[\hatpsi_k + \widehat{\rm s.e.}(\hatpsi_k)\,q\left(\frac{\alpha}{2}\right), \ \hatpsi_k + \widehat{\rm s.e.}(\hatpsi_k)\,q\left(1-\frac{\alpha}{2}\right)\right] , </math> }} | |equation=<math>{\rm CI}(\psi_k^\star) = \left[\hatpsi_k + \widehat{\rm s.e.}(\hatpsi_k)\,q\left(\frac{\alpha}{2}\right), \ \hatpsi_k + \widehat{\rm s.e.}(\hatpsi_k)\,q\left(1-\frac{\alpha}{2}\right)\right] , </math> }} | ||
| − | where $q(w)$ is the quantile of order $w$ of a ${\cal N}(0,1)$ distribution. | + | where $q(w)$ is the [http://en.wikipedia.org/wiki/Quantile quantile] of order $w$ of a ${\cal N}(0,1)$ distribution. |
{{Remarks | {{Remarks | ||
|title=Remarks | |title=Remarks | ||
| − | |text= Approximating the fraction $\hatpsi/\widehat{\rm s.e}(\hatpsi_k)$ by the normal distribution is a "good" approximation only when the number of observations $n$ is large. A better approximation should be used for small $n$. In the model $y_j = f(t_j ; \phi) + a\teps_j$, the distribution of $\hat{a}^2$ can be approximated by a chi- | + | |text= Approximating the fraction $\hatpsi/\widehat{\rm s.e}(\hatpsi_k)$ by the normal distribution is a "good" approximation only when the number of observations $n$ is large. A better approximation should be used for small $n$. In the model $y_j = f(t_j ; \phi) + a\teps_j$, the distribution of $\hat{a}^2$ can be approximated by a [http://en.wikipedia.org/wiki/Chi-squared_distribution chi-squared distribution] with $(n-d_\phi)$ [http://en.wikipedia.org/wiki/Degrees_of_freedom_%28statistics%29 degrees of freedom], where $d_\phi$ is the dimension of $\phi$. The quantiles of the normal distribution can then be replaced by those of a [http://en.wikipedia.org/wiki/Student%27s_t-distribution Student's $t$-distribution] with $(n-d_\phi)$ degrees of freedom. |
<!-- %$${\rm CI}(\psi_k) = [\hatpsi_k - \widehat{\rm s.e}(\hatpsi_k)q((1-\alpha)/2,n-d) , \hatpsi_k + \widehat{\rm s.e}(\hatpsi_k)q((1+\alpha)/2,n-d)]$$ --> | <!-- %$${\rm CI}(\psi_k) = [\hatpsi_k - \widehat{\rm s.e}(\hatpsi_k)q((1-\alpha)/2,n-d) , \hatpsi_k + \widehat{\rm s.e}(\hatpsi_k)q((1+\alpha)/2,n-d)]$$ --> | ||
<!-- %where $q(\alpha,\nu)$ is the quantile of order $\alpha$ of a $t$-distribution with $\nu$ degrees of freedom. --> | <!-- %where $q(\alpha,\nu)$ is the quantile of order $\alpha$ of a $t$-distribution with $\nu$ degrees of freedom. --> | ||
| Line 271: | Line 271: | ||
===Estimating confidence intervals using Monte Carlo simulation=== | ===Estimating confidence intervals using Monte Carlo simulation=== | ||
| − | The use of Monte Carlo methods to estimate a distribution does not require any approximation of the model. | + | The use of [http://en.wikipedia.org/wiki/Monte_Carlo_method Monte Carlo methods] to estimate a distribution does not require any approximation of the model. |
We proceed in the following way. Suppose we have found a MLE $\hatpsi$ of $\psi$. We then simulate a data vector $y^{(1)}$ by first randomly generating the vector $\teps^{(1)}$ and then calculating for $1 \leq j \leq n$, | We proceed in the following way. Suppose we have found a MLE $\hatpsi$ of $\psi$. We then simulate a data vector $y^{(1)}$ by first randomly generating the vector $\teps^{(1)}$ and then calculating for $1 \leq j \leq n$, | ||
| Line 287: | Line 287: | ||
|equation=<math> [\hat{\psi}_{k,([\frac{\alpha}{2} M])} \ , \ \hat{\psi}_{k,([ (1-\frac{\alpha}{2})M])} ], </math> }} | |equation=<math> [\hat{\psi}_{k,([\frac{\alpha}{2} M])} \ , \ \hat{\psi}_{k,([ (1-\frac{\alpha}{2})M])} ], </math> }} | ||
| − | where $[\cdot]$ denotes the integer part and $(\psi_{k,(m)},\ 1 \leq m \leq M)$ the order statistic, i.e., the parameters $(\hatpsi_k^{(m)}, 1 \leq m \leq M)$ reordered so that $\hatpsi_{k,(1)} \leq \hatpsi_{k,(2)} \leq \ldots \leq \hatpsi_{k,(M)}$. | + | where $[\cdot]$ denotes the [http://en.wikipedia.org/wiki/Floor_and_ceiling_functions integer part] and $(\psi_{k,(m)},\ 1 \leq m \leq M)$ the order statistic, i.e., the parameters $(\hatpsi_k^{(m)}, 1 \leq m \leq M)$ reordered so that $\hatpsi_{k,(1)} \leq \hatpsi_{k,(2)} \leq \ldots \leq \hatpsi_{k,(M)}$. |
| Line 301: | Line 301: | ||
===The data=== | ===The data=== | ||
| − | This modeling process is illustrated in detail in the following PK example. Let us consider a dose D=50mg of a drug | + | This modeling process is illustrated in detail in the following [http://en.wikipedia.org/wiki/Pharmacokinetics PK] example. Let us consider a dose D=50mg of a drug administered orally to a patient at time $t=0$. The concentration of the drug in the bloodstream is then measured at times $(t_j) = (0.5, 1,\,1.5,\,2,\,3,\,4,\,8,\,10,\,12,\,16,\,20,\,24).$ Here is the file {{Verbatim|individualFitting_data.txt}} with the data: |
| − | {| class="wikitable" align="center" style=" | + | {| class="wikitable" align="center" style="width: 30%;margin-left:15em" |
!| Time || Concentration | !| Time || Concentration | ||
|- | |- | ||
| Line 333: | Line 333: | ||
| − | We are going to perform the analyses for this example with the free statistical software {{Verbatim|R}}. First, we import the data and plot it to have a look: | + | We are going to perform the analyses for this example with the free statistical software [http://www.r-project.org/ {{Verbatim|R}}]. First, we import the data and plot it to have a look: |
{| cellpadding="5" cellspacing="0" | {| cellpadding="5" cellspacing="0" | ||
| − | | style="width: | + | | style="width: 50%" | |
| − | + | [[File:NewIndividual1.png|link=]] | |
| − | | style="width: | + | | style="width: 50%" | {{RcodeForTable |
|name= | |name= | ||
|code= | |code= | ||
| Line 344: | Line 344: | ||
t=pk1$time | t=pk1$time | ||
y=pk1$concentration | y=pk1$concentration | ||
| − | plot(t,y,xlab="time(hour)",ylab="concentration(mg/l)", | + | plot(t, y, xlab="time(hour)", |
| − | + | ylab="concentration(mg/l)", col="blue") | |
| + | </pre> }} | ||
|} | |} | ||
| Line 357: | Line 358: | ||
<ul> | <ul> | ||
| − | * A one compartment model with first-order absorption and linear elimination: | + | * A [http://en.wikipedia.org/wiki/Multi-compartment_model#Single-compartment_model one compartment model] with first-order [http://en.wikipedia.org/wiki/Absorption_%28pharmacokinetics%29 absorption] and linear elimination: |
{{Equation1 | {{Equation1 | ||
| Line 388: | Line 389: | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
predc1=function(t,x){ | predc1=function(t,x){ | ||
| − | f=50*x[1]/x[2]/(x[1]-x[3])*(exp(-x[3]*t)-exp(-x[1]*t)) } | + | f=50*x[1]/x[2]/(x[1]-x[3])*(exp(-x[3]*t)-exp(-x[1]*t)) |
| + | return(f)} | ||
predc2=function(t,x){ | predc2=function(t,x){ | ||
| − | + | f=50/x[1]/x[2]/x[3]*(1-exp(-x[3]*t)) | |
| − | + | f[t>x[1]]=50/x[1]/x[2]/x[3]*(1-exp(-x[3]*x[1]))*exp(-x[3]*(t[t>x[1]]-x[1])) | |
| − | f | + | return(f)} </pre> |
}} | }} | ||
| Line 406: | Line 408: | ||
We can fit these two models to our data by computing the MLE $\hatpsi_1=(\hatphi_1,\hat{a}_1)$ and $\hatpsi_2=(\hatphi_2,\hat{a}_2)$ of $\psi$ under each model: | We can fit these two models to our data by computing the MLE $\hatpsi_1=(\hatphi_1,\hat{a}_1)$ and $\hatpsi_2=(\hatphi_2,\hat{a}_2)$ of $\psi$ under each model: | ||
| − | {| cellpadding=" | + | {| cellpadding="10" cellspacing="10" |
| − | | style="width: | + | | style="width:50%" | |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
|code= | |code= | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
| − | fmin1=function(x,y,t) | + | fmin1=function(x,y,t){ |
| − | + | f=predc1(t,x) | |
| − | g=x[4] | + | g=x[4] |
| − | e=sum( ((y-f)/g)^2 + log(g^2)) | + | e=sum( ((y-f)/g)^2 + log(g^2)) |
| − | } | + | return(e)} |
| − | fmin2=function(x,y,t) | + | fmin2=function(x,y,t){ |
| − | + | f=predc2(t,x) | |
| − | g=x[4] | + | g=x[4] |
| − | e=sum( ((y-f)/g)^2 + log(g^2)) | + | e=sum( ((y-f)/g)^2 + log(g^2)) |
| − | } | + | return(e)} |
#--------- MLE -------------------------------- | #--------- MLE -------------------------------- | ||
| Line 433: | Line 435: | ||
</pre> | </pre> | ||
}} | }} | ||
| − | | style="width: | + | | style="width:50%" | |
:Here are the parameter estimation results: | :Here are the parameter estimation results: | ||
| Line 450: | Line 452: | ||
<br> | <br> | ||
| + | |||
===Assessing and selecting the PK model=== | ===Assessing and selecting the PK model=== | ||
The estimated parameters $\hatphi_1$ and $\hatphi_2$ can then be used for computing the predicted concentrations $\hat{f}_1(t)$ and $\hat{f}_2(t)$ under both models at any time $t$. These curves can then be plotted over the original data and compared: | The estimated parameters $\hatphi_1$ and $\hatphi_2$ can then be used for computing the predicted concentrations $\hat{f}_1(t)$ and $\hat{f}_2(t)$ under both models at any time $t$. These curves can then be plotted over the original data and compared: | ||
| − | {| cellpadding="5" cellspacing=" | + | {| cellpadding="5" cellspacing="0" |
| − | | style="width: | + | | style="width:50%" | |
| − | + | [[File:New_Individual2.png|link=]] | |
| − | | style="width: | + | | style="width:50%" | |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
| Line 463: | Line 466: | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
tc=seq(from=0,to=25,by=0.1) | tc=seq(from=0,to=25,by=0.1) | ||
| + | phi1=psi1[c(1,2,3)] | ||
fc1=predc1(tc,phi1) | fc1=predc1(tc,phi1) | ||
| + | phi2=psi2[c(1,2,3)] | ||
fc2=predc2(tc,phi2) | fc2=predc2(tc,phi2) | ||
plot(t,y,ylim=c(0,4.1),xlab="time (hour)", | plot(t,y,ylim=c(0,4.1),xlab="time (hour)", | ||
| − | + | ylab="concentration (mg/l)",col = "blue") | |
lines(tc,fc1, type = "l", col = "green", lwd=2) | lines(tc,fc1, type = "l", col = "green", lwd=2) | ||
lines(tc,fc2, type = "l", col = "red", lwd=2) | lines(tc,fc2, type = "l", col = "red", lwd=2) | ||
abline(a=0,b=0,lty=2) | abline(a=0,b=0,lty=2) | ||
| − | legend(13,4,c("observations", | + | legend(13,4,c("observations","first order absorption", |
| − | + | "zero order absorption"), | |
| − | + | lty=c(-1,1,1), pch=c(1,-1,-1), lwd=2, col=c("blue","green","red")) | |
| − | |||
</pre> }} | </pre> }} | ||
|} | |} | ||
| Line 482: | Line 486: | ||
Another useful goodness-of-fit plot is obtained by displaying the observations $(y_j)$ versus the predictions $\hat{y}_j=f(t_j ; \hatpsi)$ given by the models: | Another useful goodness-of-fit plot is obtained by displaying the observations $(y_j)$ versus the predictions $\hat{y}_j=f(t_j ; \hatpsi)$ given by the models: | ||
| − | {| cellpadding="5" cellspacing=" | + | {| cellpadding="5" cellspacing="0" |
| − | | style="width: | + | | style="width:50%" | |
| − | + | [[File:individual3.png|link=]] | |
| − | | style="width: | + | | style="width:50%" | |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
| Line 494: | Line 498: | ||
par(mfrow= c(1,2)) | par(mfrow= c(1,2)) | ||
| − | plot(f1,y,xlim=c(0,4),ylim=c(0,4), main="model 1") | + | plot(f1,y,xlim=c(0,4),ylim=c(0,4),main="model 1") |
abline(a=0,b=1,lty=1) | abline(a=0,b=1,lty=1) | ||
| − | plot(f2,y,xlim=c(0,4),ylim=c(0,4), main="model 2") | + | plot(f2,y,xlim=c(0,4),ylim=c(0,4),main="model 2") |
abline(a=0,b=1,lty=1) | abline(a=0,b=1,lty=1) | ||
</pre> }} | </pre> }} | ||
| Line 504: | Line 508: | ||
<br> | <br> | ||
| + | |||
===Model selection=== | ===Model selection=== | ||
| − | Again, ${\cal M}_2$ would seem to have a slight edge. This can be tested more analytically using the Bayesian Information Criteria (BIC): | + | Again, ${\cal M}_2$ would seem to have a slight edge. This can be tested more analytically using the [http://en.wikipedia.org/wiki/Bayesian_information_criterion Bayesian Information Criteria] (BIC): |
| − | {| cellpadding=" | + | {| cellpadding="10" cellspacing="10" |
| − | | style="width: | + | | style="width:50%" | |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
| Line 520: | Line 525: | ||
bic2=deviance2+log(n)*length(psi2) | bic2=deviance2+log(n)*length(psi2) | ||
</pre> }} | </pre> }} | ||
| − | | style="width: | + | | style="width:50%" | |
{{JustCodeForTable | {{JustCodeForTable | ||
|code= | |code= | ||
| Line 537: | Line 542: | ||
<br> | <br> | ||
| + | |||
===Fitting different error models=== | ===Fitting different error models=== | ||
| − | For the moment, we have only considered constant error models. However, the "observations vs predictions" figure | + | For the moment, we have only considered constant error models. However, the "observations vs predictions" figure hints that the amplitude of the residual errors may increase with the size of the predicted value. Let us therefore take a closer look at four different residual error models, each of which we will associate with the "best" structural model $f_2$: |
| − | + | {| cellpadding="2" cellspacing="8" style="text-align:left; margin-left:4%" | |
|${\cal M}_2$ || Constant error model: || $y_j=f_2(t_j;\phi_2)+a_2\teps_j$ | |${\cal M}_2$ || Constant error model: || $y_j=f_2(t_j;\phi_2)+a_2\teps_j$ | ||
|- | |- | ||
| Line 559: | Line 565: | ||
|code= | |code= | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
| − | fmin3=function(x,y,t) | + | fmin3=function(x,y,t){ |
| − | + | f=predc2(t,x) | |
| − | g=x[4]*f | + | g=x[4]*f |
| − | e=sum( ((y-f)/g)^2 + log(g^2)) | + | e=sum( ((y-f)/g)^2 + log(g^2)) |
| − | } | + | return(e)} |
| − | fmin4=function(x,y,t) | + | fmin4=function(x,y,t){ |
| − | + | f=predc2(t,x) | |
| − | g=abs(x[4])+abs(x[5])*f | + | g=abs(x[4])+abs(x[5])*f |
| − | e=sum( ((y-f)/g)^2 + log(g^2)) | + | e=sum( ((y-f)/g)^2 + log(g^2)) |
| − | } | + | return(e)} |
| − | fmin5=function(x,y,t) | + | fmin5=function(x,y,t){ |
| − | + | f=predc2(t,x) | |
| − | g=x[4] | + | g=x[4] |
| − | e=sum( ((log(y)-log(f))/g)^2 + log(g^2)) | + | e=sum( ((log(y)-log(f))/g)^2 + log(g^2)) |
| − | } | + | return(e)} |
</pre> }} | </pre> }} | ||
| Line 581: | Line 587: | ||
We can now compute the MLE $\hatpsi_3=(\hatphi_3,\hat{b}_3)$, $\hatpsi_4=(\hatphi_4,\hat{a}_4,\hat{b}_4)$ and $\hatpsi_5=(\hatphi_5,\hat{a}_5)$ of $\psi$ under models ${\cal M}_3$, ${\cal M}_4$ and ${\cal M}_5$: | We can now compute the MLE $\hatpsi_3=(\hatphi_3,\hat{b}_3)$, $\hatpsi_4=(\hatphi_4,\hat{a}_4,\hat{b}_4)$ and $\hatpsi_5=(\hatphi_5,\hat{a}_5)$ of $\psi$ under models ${\cal M}_3$, ${\cal M}_4$ and ${\cal M}_5$: | ||
| − | {| cellpadding=" | + | {| cellpadding="10" cellspacing="10" |
| − | |style="width: | + | |style="width:50%" | |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
| Line 602: | Line 608: | ||
psi5=pk.nlm5$estimate | psi5=pk.nlm5$estimate | ||
</pre> }} | </pre> }} | ||
| − | |style="width: | + | |style="width:50%" | |
{{JustCodeForTable | {{JustCodeForTable | ||
|code=<pre style="background-color: #EFEFEF; border:none; color:blue"> | |code=<pre style="background-color: #EFEFEF; border:none; color:blue"> | ||
| Line 618: | Line 624: | ||
<br> | <br> | ||
| + | |||
===Selecting the error model=== | ===Selecting the error model=== | ||
| Line 623: | Line 630: | ||
| − | {| cellpadding="5" cellspacing=" | + | {| cellpadding="5" cellspacing="0" |
| − | |style="width= | + | |style="width=50%"| |
| − | + | [[File:New_Individual4.png|link=]] | |
| − | |style="width= | + | |style="width=50%"| |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
|code= | |code= | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
| − | + | phi3=psi3[c(1,2,3)] | |
| − | + | fc3=predc2(tc,phi3) | |
| − | + | phi4=psi4[c(1,2,3)] | |
| + | fc4=predc2(tc,phi4) | ||
| + | phi5=psi5[c(1,2,3)] | ||
| + | fc5=predc2(tc,phi5) | ||
| − | plot(t,y,ylim=c(0,4.1),xlab="time (hour)", | + | par(mfrow= c(1,1)) |
| − | + | plot(t,y,ylim=c(0,4.1),xlab="time (hour)",ylab="concentration (mg/l)", | |
| − | + | col = "blue") | |
| − | + | lines(tc,fc2, type = "l", col = "red", lwd=2) | |
| − | + | lines(tc,fc3, type = "l", col = "green", lwd=2) | |
| − | + | lines(tc,fc4, type = "l", col = "cyan", lwd=2) | |
| − | + | lines(tc,fc5, type = "l", col = "magenta", lwd=2) | |
| − | + | abline(a=0,b=0,lty=2) | |
| − | + | legend(13,4,c("observations","constant error model", | |
| + | "proportional error model","combined error model","exponential error model"), | ||
| + | lty=c(-1,1,1,1,1), pch=c(1,-1,-1,-1,-1), lwd=2, | ||
| + | col=c("blue","red","green","cyan","magenta")) | ||
</pre> }} | </pre> }} | ||
| − | |} | + | |} |
| + | |||
As you can see, the three predicted concentrations obtained with models ${\cal M}_3$, ${\cal M}_4$ and ${\cal M}_5$ are quite similar. We now calculate the BIC for each: | As you can see, the three predicted concentrations obtained with models ${\cal M}_3$, ${\cal M}_4$ and ${\cal M}_5$ are quite similar. We now calculate the BIC for each: | ||
| − | {| cellpadding=" | + | {| cellpadding="10" cellspacing="10" |
| − | |style="width= | + | |style="width=50%"| |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
| Line 663: | Line 677: | ||
bic5=deviance5 + log(n)*length(psi5) | bic5=deviance5 + log(n)*length(psi5) | ||
</pre> }} | </pre> }} | ||
| − | |style="width= | + | |style="width=50%"| |
{{JustCodeForTable | {{JustCodeForTable | ||
|code= | |code= | ||
| Line 676: | Line 690: | ||
bic5 = 4.108521 | bic5 = 4.108521 | ||
</pre> }} | </pre> }} | ||
| − | |} | + | |} |
All of these BIC are lower than the constant residual error one. BIC selects the residual error model ${\cal M}_3$ with a proportional component. | All of these BIC are lower than the constant residual error one. BIC selects the residual error model ${\cal M}_3$ with a proportional component. | ||
| Line 682: | Line 696: | ||
There is not a large difference between these three error models, though the proportional and combined error models give the smallest and essentially identical BIC. We decide to use the combined error model ${\cal M}_4$ in the following (the same types of analysis could be done with the proportional error model). | There is not a large difference between these three error models, though the proportional and combined error models give the smallest and essentially identical BIC. We decide to use the combined error model ${\cal M}_4$ in the following (the same types of analysis could be done with the proportional error model). | ||
| − | A 90% confidence interval for $\psi_4$ can derived from the Hessian (i.e., the square matrix of second-order partial derivatives) of the objective function (i.e. -2 $\times \ LL$): | + | A 90% confidence interval for $\psi_4$ can derived from the Hessian (i.e., the square matrix of second-order partial derivatives) of the objective function (i.e., -2 $\times \ LL$): |
| − | {| cellpadding=" | + | {| cellpadding="10" cellspacing="10" |
| − | |style="width= | + | |style="width=50%"| |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
| Line 696: | Line 710: | ||
H4=solve(I4) | H4=solve(I4) | ||
s4=sqrt(diag(H4)*n/df) | s4=sqrt(diag(H4)*n/df) | ||
| − | delta4=s4*qt(0.5+ialpha/2,df) | + | delta4=s4*qt(0.5+ialpha/2, df) |
| + | ci4=matrix(c(psi4-delta4,psi4+delta4),ncol=2) | ||
</pre> }} | </pre> }} | ||
| − | |style="width= | + | |style="width=50%"| |
{{JustCodeForTable | {{JustCodeForTable | ||
|code= | |code= | ||
| Line 713: | Line 728: | ||
| − | We can also calculate a 90% confidence interval for $f_4(t)$ using the Central Limit Theorem (see [[#intro_individualCLT|(3)]]): | + | We can also calculate a 90% confidence interval for $f_4(t)$ using the [http://en.wikipedia.org/wiki/Central_limit_theorem Central Limit Theorem] (see [[#intro_individualCLT|(3)]]): |
| Line 720: | Line 735: | ||
|code= | |code= | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
| − | nlpredci=function(phi,f,H) | + | nlpredci=function(phi,f,H){ |
| − | { | + | dphi=length(phi) |
| − | dphi=length(phi) | + | nf=length(f) |
| − | nf=length(f) | + | H=H*n/(n-dphi) |
| − | H=H*n/(n-dphi) | + | S=H[seq(1,dphi),seq(1,dphi)] |
| − | S=H[seq(1,dphi),seq(1,dphi)] | + | G=matrix(nrow=nf,ncol=dphi) |
| − | G=matrix(nrow=nf,ncol=dphi) | + | for (k in seq(1,dphi)) { |
| − | for (k in seq(1,dphi)) { | + | dk=phi[k]*(1e-5) |
| − | + | phid=phi | |
| − | + | phid[k]=phi[k] + dk | |
| − | + | fd=predc2(tc,phid) | |
| − | + | G[,k]=(f-fd)/dk | |
| − | + | } | |
| − | } | + | M=rowSums((G%*%S)*G) |
| − | M=rowSums((G%*%S)*G) | + | deltaf=sqrt(M)*qt(0.5+alpha/2,df) |
| − | deltaf=sqrt(M)*qt(0.5+ | + | return(deltaf)} |
| − | } | ||
deltafc4=nlpredci(phi4,fc4,H4) | deltafc4=nlpredci(phi4,fc4,H4) | ||
| Line 744: | Line 758: | ||
| − | {| cellpadding="5" cellspacing=" | + | {| cellpadding="5" cellspacing="0" |
| − | |style="width= | + | |style="width=50%"| |
| − | + | [[File:NewIndividual6.png|link=]] | |
| − | |style="width= | + | |style="width=50%"| |
{{RcodeForTable | {{RcodeForTable | ||
|name= | |name= | ||
|code= | |code= | ||
<pre style="background-color: #EFEFEF; border:none"> | <pre style="background-color: #EFEFEF; border:none"> | ||
| − | plot(t,y,ylim=c(0,4.5),xlab="time (hour)", | + | plot(t,y,ylim=c(0,4.5), xlab="time (hour)", |
| − | ylab="concentration (mg/l)",col = "blue") | + | ylab="concentration (mg/l)", col="blue") |
| − | + | lines(tc,fc4, type = "l",col = "red",lwd=2) | |
| − | + | lines(tc, fc4-deltafc4, type = "l", | |
| − | + | col = "red" ,lwd=1, lty=3) | |
| − | + | lines(tc,fc4+deltafc4,type = "l", | |
| − | + | col = "red", lwd=1, lty=3) | |
| + | abline(a=0,b=0,lty=2) | ||
| + | legend(10.5,4.5,c("observed concentrations", | ||
"predicted concentration", | "predicted concentration", | ||
"CI for predicted concentration"), | "CI for predicted concentration"), | ||
| − | + | lty=c(-1,1,3),pch=c(1,-1,-1),lwd=c(2,2,1), | |
col=c("blue","red","red")) | col=c("blue","red","red")) | ||
</pre> }} | </pre> }} | ||
| − | |} | + | |} |
Alternatively, prediction intervals for $\hatpsi_4$, $\hat{f}_4(t;\hatpsi_4)$ and new observations for any time $t$ can be estimated by Monte Carlo simulation: | Alternatively, prediction intervals for $\hatpsi_4$, $\hat{f}_4(t;\hatpsi_4)$ and new observations for any time $t$ can be estimated by Monte Carlo simulation: | ||
| Line 824: | Line 840: | ||
abline(a=0,b=0,lty=2) | abline(a=0,b=0,lty=2) | ||
legend(10.5,4.5,c("observed concentrations", "predicted concentration", | legend(10.5,4.5,c("observed concentrations", "predicted concentration", | ||
| − | "CI for predicted concentration", "CI for observed concentrations"), lty=c(-1,1,3,3), | + | "CI for predicted concentration", "CI for observed concentrations"), |
| − | + | lty=c(-1,1,3,3), pch=c(1,-1,-1,-1), lwd=c(2,2,1,1), col=c("blue","red","red","green")) | |
</pre> }} | </pre> }} | ||
| − | {| cellpadding="5" cellspacing=" | + | |
| − | |style="width= | + | {| cellpadding="5" cellspacing="0" |
| − | + | |style="width=50%"| | |
| − | |style="width= | + | [[File:NewIndividual7.png|link=]] |
| + | |style="width=50%"| | ||
{{JustCodeForTable | {{JustCodeForTable | ||
|code= | |code= | ||
| Line 850: | Line 867: | ||
==Bibliography== | ==Bibliography== | ||
| + | |||
<bibtex> | <bibtex> | ||
| − | @ | + | @book{buonaccorsi2010measurement, |
| − | title={ | + | title={Measurement Error: Models, Methods, and Applications}, |
| − | author={ | + | author={Buonaccorsi, J.P.}, |
| − | + | isbn={9781420066586}, | |
| − | + | lccn={2009048849}, | |
| − | + | series={Chapman & Hall/CRC Interdisciplinary Statistics}, | |
| − | + | url={http://books.google.fr/books?id=QVtVmaCqLHMC}, | |
| − | year={ | + | year={2010}, |
publisher={Taylor & Francis} | publisher={Taylor & Francis} | ||
} | } | ||
| − | </bibtex> | + | </bibtex><bibtex> |
| − | <bibtex> | ||
@book{carroll2010measurement, | @book{carroll2010measurement, | ||
title={Measurement Error in Nonlinear Models: A Modern Perspective, Second Edition}, | title={Measurement Error in Nonlinear Models: A Modern Perspective, Second Edition}, | ||
| Line 875: | Line 892: | ||
} | } | ||
</bibtex> | </bibtex> | ||
| − | + | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
<bibtex> | <bibtex> | ||
@book{fitzmaurice2004applied, | @book{fitzmaurice2004applied, | ||
| Line 896: | Line 902: | ||
url={http://books.google.fr/books?id=gCoTIFejMgYC}, | url={http://books.google.fr/books?id=gCoTIFejMgYC}, | ||
year={2004}, | year={2004}, | ||
| + | publisher={Wiley} | ||
| + | } | ||
| + | </bibtex> | ||
| + | <bibtex> | ||
| + | @book{gallant2009nonlinear, | ||
| + | title={Nonlinear Statistical Models}, | ||
| + | author={Gallant, A.R.}, | ||
| + | isbn={9780470317372}, | ||
| + | series={Wiley Series in Probability and Statistics}, | ||
| + | url={http://books.google.fr/books?id=imv-NMozseEC}, | ||
| + | year={2009}, | ||
publisher={Wiley} | publisher={Wiley} | ||
} | } | ||
| Line 917: | Line 934: | ||
</bibtex> | </bibtex> | ||
<bibtex> | <bibtex> | ||
| − | @book{ | + | @book{ross1990nonlinear, |
| − | title={ | + | title={Nonlinear estimation}, |
| − | author={ | + | author={Ross, G.J.S.}, |
| − | + | isbn={9780387972787}, | |
| − | year={ | + | lccn={90032797}, |
| − | publisher={Springer | + | series={Springer series in statistics}, |
| + | url={http://books.google.fr/books?id=7LkyzdLMghIC}, | ||
| + | year={1990}, | ||
| + | publisher={Springer-Verlag} | ||
} | } | ||
</bibtex> | </bibtex> | ||
| Line 936: | Line 956: | ||
publisher={Wiley} | publisher={Wiley} | ||
} | } | ||
| − | </bibtex> | + | </bibtex><bibtex> |
| − | <bibtex> | + | @article{serroyen2009nonlinear, |
| − | @ | + | title={Nonlinear models for longitudinal data}, |
| − | title={Nonlinear | + | author={Serroyen, J. and Molenberghs, G. and Verbeke, G. and Davidian, M. }, |
| − | author={ | + | journal={The American Statistician}, |
| − | + | volume={63}, | |
| − | + | number={4}, | |
| − | + | pages={378-388}, | |
| − | + | year={2009}, | |
| − | year={ | + | publisher={Taylor & Francis} |
| − | publisher={ | ||
} | } | ||
</bibtex> | </bibtex> | ||
<bibtex> | <bibtex> | ||
| − | @book{ | + | @book{wolberg2006data, |
| − | title={ | + | title={Data analysis using the method of least squares: extracting the most information from experiments}, |
| − | author={ | + | author={Wolberg, J.R.}, |
| − | + | volume={1}, | |
| − | + | year={2006}, | |
| − | + | publisher={Springer Berlin, Germany} | |
| − | year={ | ||
| − | publisher={ | ||
} | } | ||
</bibtex> | </bibtex> | ||
| Line 965: | Line 982: | ||
|linkBack=Overview | |linkBack=Overview | ||
|linkNext=What is a model? A joint probability distribution! }} | |linkNext=What is a model? A joint probability distribution! }} | ||
| − | |||
Latest revision as of 14:58, 28 August 2013
Contents
- 1 Overview
- 2 Model and methods for the individual approach
- 2.1 Defining a model
- 2.2 Choosing a residual error model
- 2.3 Tasks
- 2.4 Selecting structural and residual error models
- 2.5 Parameter estimation
- 2.6 Computing the Fisher information matrix
- 2.7 Deriving confidence intervals for parameters
- 2.8 Deriving confidence intervals for predictions
- 2.9 Estimating confidence intervals using Monte Carlo simulation
- 3 A PK example
- 4 Bibliography
Overview
Before we start looking at modeling a whole population at the same time, we are going to consider only one individual from that population. Much of the basic methodology for modeling one individual follows through to population modeling. We will see that when stepping up from one individual to a population, the difference is that some parameters shared by individuals are considered to be drawn from a probability distribution.
Let us begin with a simple example. An individual receives 100mg of a drug at time $t=0$. At that time and then every hour for fifteen hours, the concentration of a marker in the bloodstream is measured and plotted against time:
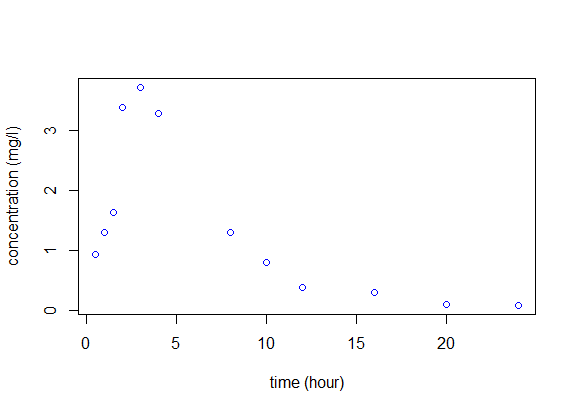
We aim to find a mathematical model to describe what we see in the figure. The eventual goal is then to extend this approach to the simultaneous modeling of a whole population.
Model and methods for the individual approach
Defining a model
In our example, the concentration is a continuous variable, so we will try to use continuous functions to model it. Different types of data (e.g., count data, categorical data, time-to-event data, etc.) require different types of models. All of these data types will be considered in due time, but for now let us concentrate on a continuous data model.
A model for continuous data can be represented mathematically as follows:
where:
- $f$ is called the structural model. It corresponds to the basic type of curve we suspect the data is following, e.g., linear, logarithmic, exponential, etc. Sometimes, a model of the associated biological processes leads to equations that define the curve's shape.
- $(t_1,t_2,\ldots , t_n)$ is the vector of observation times. Here, $t_1 = 0$ hours and $t_n = t_{16} = 15$ hours.
- $\psi=(\psi_1, \psi_2, \ldots, \psi_d)$ is a vector of $d$ parameters that influences the value of $f$.
- $(e_1, e_2, \ldots, e_n)$ are called the residual errors. Usually, we suppose that they come from some centered probability distribution: $\esp{e_j} =0$.
In fact, we usually state a continuous data model in a slightly more flexible way:
\(
y_{j} = f(t_j ; \psi) + g(t_j ; \psi)\teps_j , \quad \quad 1\leq j \leq n,
\)
|
(1) |
where now:
- $g$ is called the residual error model. It may be a function of the time $t_j$ and parameters $\psi$.
- $(\teps_1, \teps_2, \ldots, \teps_n)$ are the normalized residual errors. We suppose that these come from a probability distribution which is centered and has unit variance: $\esp{\teps_j} = 0$ and $\var{\teps_j} =1$.
Choosing a residual error model
The choice of a residual error model $g$ is very flexible, and allows us to account for many different hypotheses we may have on the error's distribution. Let $f_j=f(t_j;\psi)$. Here are some simple error models.
- Constant error model: $g=a$. That is, $y_j=f_j+a\teps_j$.
- Proportional error model: $g=b\,f$. That is, $y_j=f_j+bf_j\teps_j$. This is for when we think the magnitude of the error is proportional to the value of the predicted value $f$.
- Combined error model: $g=a+b f$. Here, $y_j=f_j+(a+bf_j)\teps_j$.
- Alternative combined error model: $g^2=a^2+b^2f^2$. Here, $y_j=f_j+\sqrt{a^2+b^2f_j^2}\teps_j$.
- Exponential error model: here, the model is instead $\log(y_j)=\log(f_j) + a\teps_j$, that is, $g=a$. It is exponential in the sense that if we exponentiate, we end up with $y_j = f_j e^{a\teps_j}$.
Tasks
To model a vector of observations $y = (y_j,\, 1\leq j \leq n$) we must perform several tasks:
- Select a structural model $f$ and a residual error model $g$.
- Estimate the model's parameters $\psi$.
- Assess and validate the selected model.
Selecting structural and residual error models
As we are interested in parametric modeling, we must choose parametric structural and residual error models. In the absence of biological (or other) information, we might suggest possible structural models just by looking at the graphs of time-evolution of the data. For example, if $y_j$ is increasing with time, we might suggest an affine, quadratic or logarithmic model, depending on the approximate trend of the data. If $y_j$ is instead decreasing ever slower to zero, an exponential model might be appropriate.
However, often we have biological (or other) information to help us make our choice. For instance, if we have a system of differential equations describing how the drug is eliminated from the body, its solution may provide the formula (i.e., structural model) we are looking for.
As for the residual error model, if it is not immediately obvious which one to choose, several can be tested in conjunction with one or several possible structural models. After parameter estimation, each structural and residual error model pair can be assessed, compared against the others, and/or validated in various ways.
Now we can have a first look at parameter estimation, and further on, model assessment and validation.
Parameter estimation
Given the observed data and the choice of a parametric model to describe it, our goal becomes to find the "best" parameters for the model. A traditional framework to solve this kind of problem is called maximum likelihood estimation or MLE, in which the "most likely" parameters are found, given the data that was observed.
The likelihood $L$ is a function defined as:
i.e., the conditional joint density function of $(y_j)$ given the parameters $\psi$, but looked at as if the data are known and the parameters not. The $\hat{\psi}$ which maximizes $L$ is known as the maximum likelihood estimator.
Suppose that we have chosen a structural model $f$ and residual error model $g$. If we assume for instance that $ \teps_j \sim_{i.i.d} {\cal N}(0,1)$, then the $y_j$ are independent of each other and (1) means that:
Due to this independence, the pdf of $y = (y_1, y_2, \ldots, y_n)$ is the product of the pdfs of each $y_j$:
This is the same thing as the likelihood function $L$ when seen as a function of $\psi$. Maximizing $L$ is equivalent to minimizing the deviance, i.e., -2 $\times$ the $\log$-likelihood ($LL$):
\(\begin{eqnarray}
\hat{\psi} &=& \argmin{\psi} \left\{ -2 \,LL \right\}\\
&=& \argmin{\psi} \left\{
\sum_{j=1}^n \log\left(g(t_j ; \psi)^2\right) + \sum_{j=1}^n \left(\displaystyle{ \frac{y_j - f(t_j ; \psi)}{g(t_j ; \psi)} }\right)^2 \right\} .
\end{eqnarray}\)
|
(2) |
This minimization problem does not usually have an analytical solution for nonlinear models, so an optimization procedure needs to be used.
However, for a few specific models, analytical solutions do exist.
For instance, suppose we have a constant error model: $y_{j} = f(t_j ; \psi) + a \, \teps_j,\,\, 1\leq j \leq n,$ that is: $g(t_j;\psi) = a$. In practice, $f$ is not itself a function of $a$, so we can write $\psi = (\phi,a)$ and therefore: $y_{j} = f(t_j ; \phi) + a \, \teps_j.$ Thus, (2) simplifies to:
The solution is then:
where $\hat{a}^2$ is found by setting the partial derivative of $-2LL$ to zero.
Whether this has an analytical solution or not depends on the form of $f$. For example, if $f(t_j;\phi)$ is just a linear function of the components of the vector $\phi$, we can represent it as a matrix $F$ whose $j$th row gives the coefficients at time $t_j$. Therefore, we have the matrix equation $y = F \phi + a \teps$.
The solution for $\hat{\phi}$ is thus the least-squares one, and for $\hat{a}^2$ it is the same as before:
Computing the Fisher information matrix
The Fisher information is a way of measuring the amount of information that an observable random variable carries about an unknown parameter upon which its probability distribution depends.
Let $\psis $ be the true unknown value of $\psi$, and let $\hatpsi$ be the maximum likelihood estimate of $\psi$. If the observed likelihood function is sufficiently smooth, asymptotic theory for maximum-likelihood estimation holds and
\(
I_n(\psis)^{\frac{1}{2} }(\hatpsi-\psis) \limite{n\to \infty}{} {\mathcal N}(0,\id) ,
\)
|
(3) |
where $I_n(\psis)$ is (minus) the Hessian (i.e., the matrix of the second derivatives) of the log-likelihood:
is the observed Fisher information matrix. Here, "observed" means that it is a function of observed variables $y_1,y_2,\ldots,y_n$.
Thus, an estimate of the covariance of $\hatpsi$ is the inverse of the observed Fisher information matrix as expressed by the formula:
Deriving confidence intervals for parameters
Let $\psi_k$ be the $k$th of $d$ components of $\psi$. Imagine that we have estimated $\psi_k$ with $\hatpsi_k$, the $k$th component of the MLE $\hatpsi$, that is, a random variable that converges to $\psi_k^{\star}$ when $n \to \infty$ under very general conditions.
An estimator of its variance is the $k$th element of the diagonal of the covariance matrix $C(\hatpsi)$:
We can thus derive an estimator of its standard error:
and a confidence interval of level $1-\alpha$ for $\psi_k^\star$:
where $q(w)$ is the quantile of order $w$ of a ${\cal N}(0,1)$ distribution.
Deriving confidence intervals for predictions
The structural model $f$ can be predicted for any $t$ using the estimated value $f(t; \hatphi)$. For that $t$, we can then derive a confidence interval for $f(t,\phi)$ using the estimated variance of $\hatphi$. Indeed, as a first approximation we have:
where $\nabla f(t,\phis)$ is the gradient of $f$ at $\phis$, i.e., the vector of the first-order partial derivatives of $f$ with respect to the components of $\phi$, evaluated at $\phis$. Of course, we do not actually know $\phis$, but we can estimate $\nabla f(t,\phis)$ with $\nabla f(t,\hatphi)$. The variance of $f(t ; \hatphi)$ can then be estimated by
We can then derive an estimate of the standard error of $f (t,\hatphi)$ for any $t$:
and a confidence interval of level $1-\alpha$ for $f(t ; \phi^\star)$:
Estimating confidence intervals using Monte Carlo simulation
The use of Monte Carlo methods to estimate a distribution does not require any approximation of the model.
We proceed in the following way. Suppose we have found a MLE $\hatpsi$ of $\psi$. We then simulate a data vector $y^{(1)}$ by first randomly generating the vector $\teps^{(1)}$ and then calculating for $1 \leq j \leq n$,
In a sense, this gives us an example of "new" data from the "same" model. We can then compute a new MLE $\hat{\psi}^{(1)}$ of $\psi$ using $y^{(1)}$.
Repeating this process $M$ times gives $M$ estimates of $\psi$ from which we can obtain an empirical estimation of the distribution of $\hatpsi$, or any quantile we like.
Any confidence interval for $\psi_k$ (resp. $f(t,\psi_k)$) can then be approximated by a prediction interval for $\hatpsi_k$ (resp. $f(t,\hatpsi_k)$). For instance, a two-sided confidence interval of level $1-\alpha$ for $\psi_k^\star$ can be estimated by the prediction interval
where $[\cdot]$ denotes the integer part and $(\psi_{k,(m)},\ 1 \leq m \leq M)$ the order statistic, i.e., the parameters $(\hatpsi_k^{(m)}, 1 \leq m \leq M)$ reordered so that $\hatpsi_{k,(1)} \leq \hatpsi_{k,(2)} \leq \ldots \leq \hatpsi_{k,(M)}$.
A PK example
In the real world, it is often not enough to look at the data, choose one possible model and estimate the parameters. The chosen structural model may or may not be "good" at representing the data. It may be good but the chosen residual error model bad, meaning that the overall model is poor, and so on. That is why in practice we may want to try out several structural and residual error models. After performing parameter estimation for each model, various assessment tasks can then be performed in order to conclude which model is best.
The data
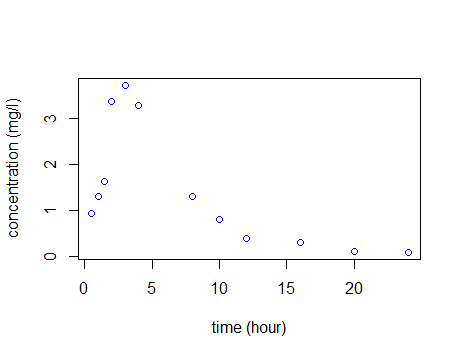
This modeling process is illustrated in detail in the following PK example. Let us consider a dose D=50mg of a drug administered orally to a patient at time $t=0$. The concentration of the drug in the bloodstream is then measured at times $(t_j) = (0.5, 1,\,1.5,\,2,\,3,\,4,\,8,\,10,\,12,\,16,\,20,\,24).$ Here is the file individualFitting_data.txt with the data:
| Time | Concentration |
|---|---|
| 0.5 | 0.94 |
| 1.0 | 1.30 |
| 1.5 | 1.64 |
| 2.0 | 3.38 |
| 3.0 | 3.72 |
| 4.0 | 3.29 |
| 8.0 | 1.31 |
| 10.0 | 0.80 |
| 12.0 | 0.39 |
| 16.0 | 0.31 |
| 20.0 | 0.10 |
| 24.0 | 0.09 |
We are going to perform the analyses for this example with the free statistical software R. First, we import the data and plot it to have a look:
|
|
Fitting two PK models
We are going to consider two possible structural models that may describe the observed time-course of the concentration:
- A one compartment model with first-order absorption and linear elimination:
- A one compartment model with zero-order absorption and linear elimination:
We define each of these functions in R:
We then define two models ${\cal M}_1$ and ${\cal M}_2$ that assume (for now) constant residual error models:
We can fit these two models to our data by computing the MLE $\hatpsi_1=(\hatphi_1,\hat{a}_1)$ and $\hatpsi_2=(\hatphi_2,\hat{a}_2)$ of $\psi$ under each model:
|
Assessing and selecting the PK model
The estimated parameters $\hatphi_1$ and $\hatphi_2$ can then be used for computing the predicted concentrations $\hat{f}_1(t)$ and $\hat{f}_2(t)$ under both models at any time $t$. These curves can then be plotted over the original data and compared:
|
|
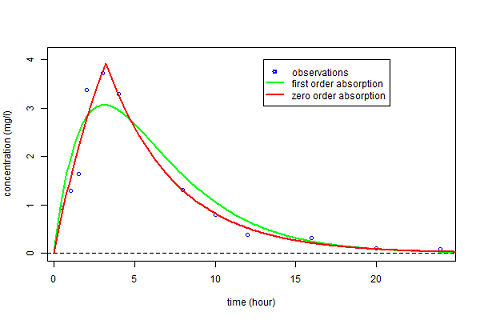
We clearly see that a much better fit is obtained with model ${\cal M}_2$, i.e., the one assuming a zero-order absorption process.
Another useful goodness-of-fit plot is obtained by displaying the observations $(y_j)$ versus the predictions $\hat{y}_j=f(t_j ; \hatpsi)$ given by the models:
|
|
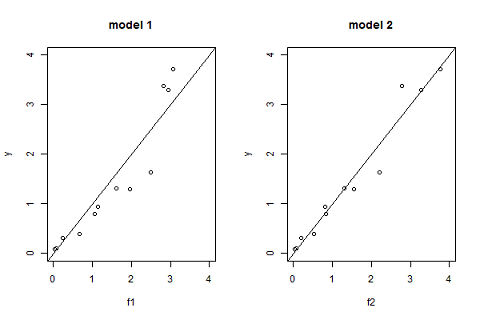
Model selection
Again, ${\cal M}_2$ would seem to have a slight edge. This can be tested more analytically using the Bayesian Information Criteria (BIC):
A smaller BIC is better. Therefore, this also suggests that model ${\cal M}_2$ should be selected.
Fitting different error models
For the moment, we have only considered constant error models. However, the "observations vs predictions" figure hints that the amplitude of the residual errors may increase with the size of the predicted value. Let us therefore take a closer look at four different residual error models, each of which we will associate with the "best" structural model $f_2$:
| ${\cal M}_2$ | Constant error model: | $y_j=f_2(t_j;\phi_2)+a_2\teps_j$ |
| ${\cal M}_3$ | Proportional error model: | $y_j=f_2(t_j;\phi_3)+b_3f_2(t_j;\phi_3)\teps_j$ |
| ${\cal M}_4$ | Combined error model: | $y_j=f_2(t_j;\phi_4)+(a_4+b_4f_2(t_j;\phi_4))\teps_j$ |
| ${\cal M}_5$ | Exponential error model: | $\log(y_j)=\log(f_2(t_j;\phi_5)) + a_5\teps_j$. |
The three new ones need to be entered into R:
We can now compute the MLE $\hatpsi_3=(\hatphi_3,\hat{b}_3)$, $\hatpsi_4=(\hatphi_4,\hat{a}_4,\hat{b}_4)$ and $\hatpsi_5=(\hatphi_5,\hat{a}_5)$ of $\psi$ under models ${\cal M}_3$, ${\cal M}_4$ and ${\cal M}_5$:
Selecting the error model
As before, these curves can be plotted over the original data and compared:
|
|
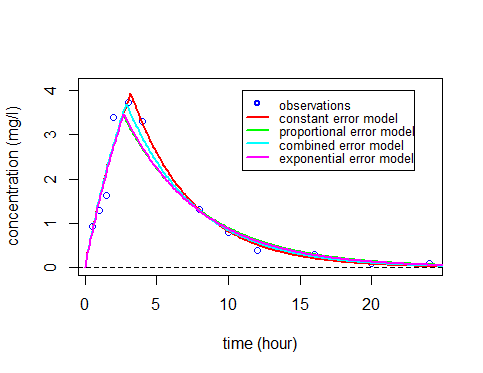
As you can see, the three predicted concentrations obtained with models ${\cal M}_3$, ${\cal M}_4$ and ${\cal M}_5$ are quite similar. We now calculate the BIC for each:
All of these BIC are lower than the constant residual error one. BIC selects the residual error model ${\cal M}_3$ with a proportional component.
There is not a large difference between these three error models, though the proportional and combined error models give the smallest and essentially identical BIC. We decide to use the combined error model ${\cal M}_4$ in the following (the same types of analysis could be done with the proportional error model).
A 90% confidence interval for $\psi_4$ can derived from the Hessian (i.e., the square matrix of second-order partial derivatives) of the objective function (i.e., -2 $\times \ LL$):
We can also calculate a 90% confidence interval for $f_4(t)$ using the Central Limit Theorem (see (3)):
This can then be plotted:
|
|
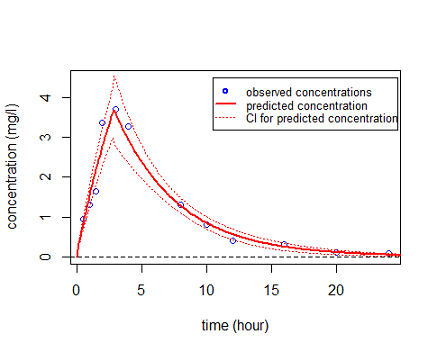
Alternatively, prediction intervals for $\hatpsi_4$, $\hat{f}_4(t;\hatpsi_4)$ and new observations for any time $t$ can be estimated by Monte Carlo simulation:
|
|
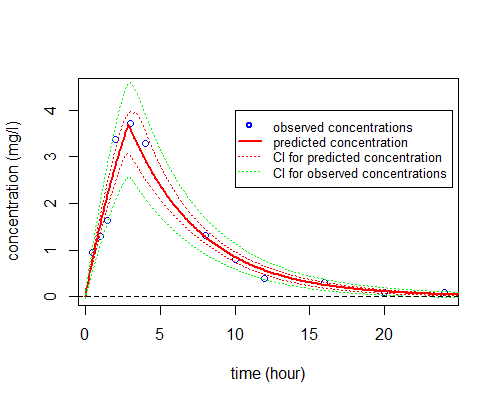
The R code and input data used in this section can be downloaded here: https://wiki.inria.fr/wikis/popix/images/a/a1/R_IndividualFitting.rar.
Bibliography
Buonaccorsi, J.P. - Measurement Error: Models, Methods, and Applications
- Taylor & Francis,2010
- http://books.google.fr/books?id=QVtVmaCqLHMC
BibtexAuthor : Buonaccorsi, J.P.
Title : Measurement Error: Models, Methods, and Applications
In : -
Address :
Date : 2010
Carroll, R.J., Ruppert, D., Stefanski, L.A., Crainiceanu, C.M. - Measurement Error in Nonlinear Models: A Modern Perspective, Second Edition
- Taylor & Francis,2010
- http://books.google.fr/books?id=9kBx5CPZCqkC
BibtexAuthor : Carroll, R.J., Ruppert, D., Stefanski, L.A., Crainiceanu, C.M.
Title : Measurement Error in Nonlinear Models: A Modern Perspective, Second Edition
In : -
Address :
Date : 2010
Fitzmaurice, G.M., Laird, N.M., Ware, J.H. - Applied Longitudinal Analysis
- Wiley,2004
- http://books.google.fr/books?id=gCoTIFejMgYC
BibtexAuthor : Fitzmaurice, G.M., Laird, N.M., Ware, J.H.
Title : Applied Longitudinal Analysis
In : -
Address :
Date : 2004
Gallant, A.R. - Nonlinear Statistical Models
- Wiley,2009
- http://books.google.fr/books?id=imv-NMozseEC
BibtexAuthor : Gallant, A.R.
Title : Nonlinear Statistical Models
In : -
Address :
Date : 2009
Huet, S., Bouvier, A., Poursat, M.A., Jolivet, E. - Statistical tools for nonlinear regression: a practical guide with S-PLUS and R examples
Ritz, C., Streibig, J.C. - Nonlinear regression with R
- Vol. 33, Springer New York,2008
- BibtexAuthor : Ritz, C., Streibig, J.C.
Title : Nonlinear regression with R
In : -
Address :
Date : 2008
Ross, G.J.S. - Nonlinear estimation
- Springer-Verlag,1990
- http://books.google.fr/books?id=7LkyzdLMghIC
BibtexAuthor : Ross, G.J.S.
Title : Nonlinear estimation
In : -
Address :
Date : 1990
Seber, G.A.F., Wild, C.J. - Nonlinear Regression
- Wiley,2003
- http://books.google.fr/books?id=YBYlCpBNo\_cC
BibtexAuthor : Seber, G.A.F., Wild, C.J.
Title : Nonlinear Regression
In : -
Address :
Date : 2003
Serroyen, J., Molenberghs, G., Verbeke, G., Davidian, M. - Nonlinear models for longitudinal data
- The American Statistician 63(4):378-388,2009
- BibtexAuthor : Serroyen, J., Molenberghs, G., Verbeke, G., Davidian, M.
Title : Nonlinear models for longitudinal data
In : The American Statistician -
Address :
Date : 2009
Wolberg, J.R. - Data analysis using the method of least squares: extracting the most information from experiments
- Vol. 1, Springer Berlin, Germany,2006
- BibtexAuthor : Wolberg, J.R.
Title : Data analysis using the method of least squares: extracting the most information from experiments
In : -
Address :
Date : 2006
 |
 |