Overview
(If you are experiencing problems with the display of the mathematical formula, you can either try to use another browser, or use this link which should work smoothly: http://popix.lixoft.net)
$ \def\simulix{\mathsf{simulix} } $
The desire to model a biological or physical phenomenon often arises when we are able to record some observations issued from that phenomenon. Nothing would be more natural therefore than to begin this introduction by looking at some observed data.
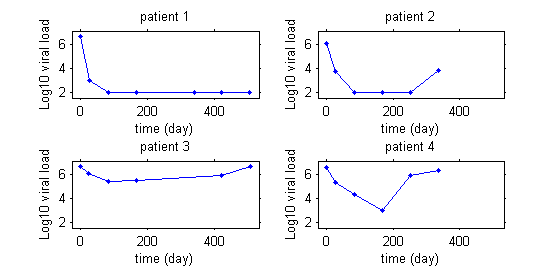
This first plot displays the viral load of four patients with hepatitis C who started a treatment at time $t=0$.
|
|
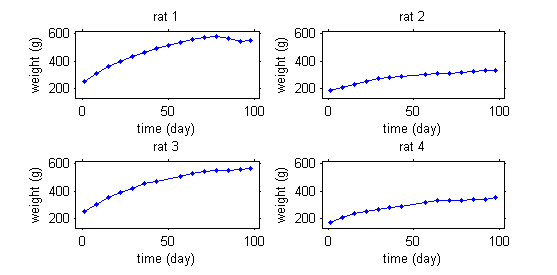
This second example involves weight data for rats measured over 14 weeks, for a sub-chronic toxicity study related to the question of genetically modified corn.
|
|
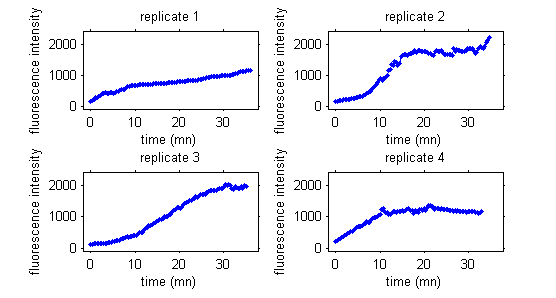
In this third example, data are fluorescence intensities measured over time in a cellular biology experiment.
|
|
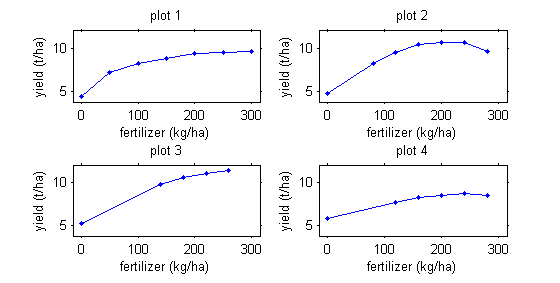
Note that repeated measurements are not necessarily always functions of time.
For example, we may be interested in corn production as a function of fertilizer quantity.
|
|
Even though these examples come from quite different domains, in each case the data is made up of repeated measurements on several individuals from a population. What we will call a "population approach" is therefore relevant for characterizing and modeling this data. The modeling goal is thus twofold: characterize the biological or physical phenomena observed for each individual, and secondly, the variability seen between individuals.
In the example with the rats, the model needs to integrate a growth model that describes how a rat's weight increases with time, and a statistical model that describes why these kinetics can vary from one rat to another. The goal is thus to finish with a "typical" curve for the population (in red) and to be able to explain the variability in the individual's curves (in green) around this population curve.
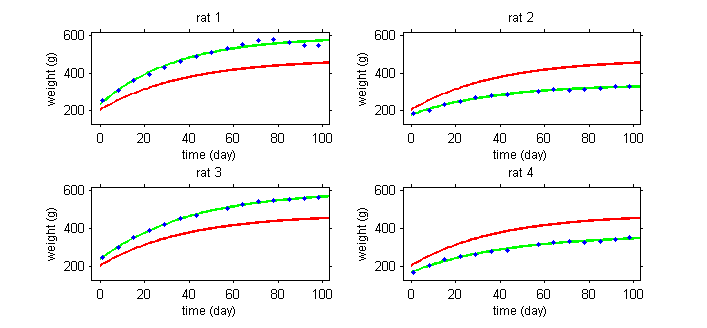
The model will explain some of this variability by individual covariates such as sex or diet (rats 1 and 3 are male while rats 2 and 4 are female), but some of the variability will remain unexplained and will be considered as random. Integrating into the same model effects considered fixed and others considered random leads naturally to the use of mixed-effects models.
An alternative yet equivalent approach considers this model as a hierarchical one: each curve is described by a single model, and the variability between individual models is described by a population model. In the case of parametric models, this means that the observations for a given individual are described by a model of the observations that depends on a vector of individual parameters: this is the classic individual approach. The population approach is then a direct extension of the individual approach: we add a component to the model that describes the variability of the individual parameters within the population.
A model can thus be seen as a joint probability distribution, which can easily be extended to the case where other variables in the model are considered as random variables: covariates, population parameters, the design, etc. The hierarchical structure of the model leads to a natural decomposition of the joint distribution into a product of conditional and marginal distributions.
Models for individual parameters and models for observations are described in the Models chapter. In particular, models for continuous observations, categorical data, count data and survival data are presented and illustrated by various examples. Extensions for mixture models, hidden Markov models and stochastic differential equation based models are also presented.
The Tasks & Tools chapter presents practical examples of using these models: exploration and visualization, estimation, model diagnostics, model selection and simulation. All approaches and proposed methods are rigorously detailed in the Methods chapter.
The main purpose of a model is to be used. Mathematical modeling and statistics remain useful tools for many disciplines (biology, agronomy, environmental studies, pharmacology, etc.), but it is important that these tools are used properly. The various software packages used in this wiki have been developed with this in mind: they serve the modeler well, while fully complying with a coherent mathematical formalism and using well-known and theoretically justified methods.
Tools for model exploration ($\mlxplore$), modeling ($\monolix$) and simulation ($\simulix$) use the same model coding language $\mlxtran$. This allows us to define a complete workflow using the same model implementation, i.e., to run several different tasks based on the same model.
$\mlxtran$ is extremely flexible and well-adapted to implementing complex mixed-effects models. With $\mlxtran$ we can easily write ODE-based models, implement pharmacokinetic models with complex administration schedules, include inter-individual variability in parameters, define statistical models for covariates, etc. Another crucial property of $\mlxtran$ is that it rigorously adopts the model representation formalism proposed in $\wikipopix$. In other words, the model implementation is fully consistent with its mathematical representation.
$\mlxplore$ provides a clear graphical interface that allows us to visualize not only the structural model but also the statistical model, which is of fundamental importance in the population approach. We can visualize for instance the impact of covariates and inter-individual variability of model parameters on predictions. $\mlxplore$ is an ideal tool for teaching or discovering what a pharmacokinetic model is, for example.
The algorithms implemented in $\monolix$ (Stochastic Approximation of EM, MCMC, Simulated Annealing, Importance Sampling, etc.) are extremely efficient for a wide variety of complex models. Furthermore, convergence of SAEM and its extensions (mixture models, hidden Markov models, SDE-based models, censored data, etc.) has been rigorously proved and published in statistical journals.
$\simulix$ is a model computation engine which enables us to simulate a $\mlxtran$ model from within various environments. $\simulix$ is now available for the Matlab and R platforms, allowing any user to combine the flexibility of R and Matlab scripts with the power of $\mlxtran$ in order to easily encode complex models and simulate data.
For these reasons, $\wikipopix$ and these tools can be used with confidence for training and teaching. This is even more the case because $\mlxplore$, $\monolix$ and $\simulix$ are free for academic research and education purposes.
 |