Difference between revisions of "Estimation of the log-likelihood"
m |
m |
||
| Line 18: | Line 18: | ||
\def\tqpsii{\tilde{p}_{\psi_i}} | \def\tqpsii{\tilde{p}_{\psi_i}} | ||
\def\tppsii{\tilde{\pmacro}} | \def\tppsii{\tilde{\pmacro}} | ||
| + | \def\petai{\pmacro} | ||
| + | \def\pcetaiyi{\pmacro} | ||
| + | \def\pyietai{\pmacro} | ||
| + | \def\pcyietai{\pmacro} | ||
| + | \def\pphii{\pmacro} | ||
| + | \def\pyiphii{\pmacro} | ||
| + | \def\pcyiphii{\pmacro} | ||
| + | \def\pcphiiyi{\pmacro} | ||
| + | \def\bphi{\boldsymbol{\phi}} | ||
<!-- .......... --> | <!-- .......... --> | ||
Revision as of 15:09, 13 May 2013
$ \def\ieta{m} \def\Meta{M} \def\imh{\ell} \def\ceta{\tilde{\eta}} \def\cpsi{\tilde{\psi}} \def\transpose{t} \newcommand{\Dt}[1]{\partial_\theta #1} \newcommand{\DDt}[1]{\partial^2_{\theta} #1} \newcommand{\cov}[1]{\mbox{Cov}\left(#1\right)} \def\jparam{j} \newcommand{\Dphi}[1]{\partial_\phi #1} \newcommand{\Dpsi}[1]{\partial_\psi #1} \def\llike{\cal LL} \def\tqpsii{\tilde{p}_{\psi_i}} \def\tppsii{\tilde{\pmacro}} \def\petai{\pmacro} \def\pcetaiyi{\pmacro} \def\pyietai{\pmacro} \def\pcyietai{\pmacro} \def\pphii{\pmacro} \def\pyiphii{\pmacro} \def\pcyiphii{\pmacro} \def\pcphiiyi{\pmacro} \def\bphi{\boldsymbol{\phi}} \newcommand{\argmin}[1]{ \mathop{\rm arg} \mathop{\rm min}\limits_{#1} } \newcommand{\argmax}[1]{ \mathop{\rm arg} \mathop{\rm max}\limits_{#1} } \newcommand{\nominal}[1]{#1^{\star}} \newcommand{\psis}{\psi{^\star}} \newcommand{\phis}{\phi{^\star}} \newcommand{\hpsi}{\hat{\psi}} \newcommand{\hphi}{\hat{\phi}} \newcommand{\teps}{\varepsilon} \newcommand{\limite}[2]{\mathop{\longrightarrow}\limits_{\mathrm{#1}}^{\mathrm{#2}}} \newcommand{\DDt}[1]{\partial^2_\theta #1} \def\cpop{c_{\rm pop}} \def\Vpop{V_{\rm pop}} \def\iparam{l} \newcommand{\trcov}[1]{#1} \def\bu{\boldsymbol{u}} \def\bt{\boldsymbol{t}} \def\bT{\boldsymbol{T}} \def\by{\boldsymbol{y}} \def\bx{\boldsymbol{x}} \def\bc{\boldsymbol{c}} \def\bw{\boldsymbol{w}} \def\bz{\boldsymbol{z}} \def\bpsi{\boldsymbol{\psi}} \def\bbeta{\beta} \def\aref{a^\star} \def\kref{k^\star} \def\model{M} \def\hmodel{m} \def\mmodel{\mu} \def\imodel{H} \def\thmle{\hat{\theta}} \def\ofim{I^{\rm obs}} \def\efim{I^{\star}} \def\Imax{\rm Imax} \def\probit{\rm probit} \def\vt{t} \def\id{\rm Id} \def\teta{\tilde{\eta}} \newcommand{\eqdef}{\mathop{=}\limits^{\mathrm{def}}} \newcommand{\deriv}[1]{\frac{d}{dt}#1(t)} \newcommand{\pred}[1]{\tilde{#1}} \def\phis{\phi{^\star}} \def\hphi{\tilde{\phi}} \def\hw{\tilde{w}} \def\hpsi{\tilde{\psi}} \def\hatpsi{\hat{\psi}} \def\hatphi{\hat{\phi}} \def\psis{\psi{^\star}} \def\transy{u} \def\psipop{\psi_{\rm pop}} \newcommand{\psigr}[1]{\hat{\bpsi}_{#1}} \newcommand{\Vgr}[1]{\hat{V}_{#1}} \def\pmacro{\text{p}} \def\py{\pmacro} \def\pt{\pmacro} \def\pc{\pmacro} \def\pu{\pmacro} \def\pyi{\pmacro} \def\pyj{\pmacro} \def\ppsi{\pmacro} \def\ppsii{\pmacro} \def\pcpsith{\pmacro} \def\pcpsiiyi{\pmacro} \def\pth{\pmacro} \def\pypsi{\pmacro} \def\pcypsi{\pmacro} \def\ppsic{\pmacro} \def\pcpsic{\pmacro} \def\pypsic{\pmacro} \def\pypsit{\pmacro} \def\pcypsit{\pmacro} \def\pypsiu{\pmacro} \def\pcypsiu{\pmacro} \def\pypsith{\pmacro} \def\pypsithcut{\pmacro} \def\pypsithc{\pmacro} \def\pcypsiut{\pmacro} \def\pcpsithc{\pmacro} \def\pcthy{\pmacro} \def\pyth{\pmacro} \def\pcpsiy{\pmacro} \def\pz{\pmacro} \def\pw{\pmacro} \def\pcwz{\pmacro} \def\pw{\pmacro} \def\pcyipsii{\pmacro} \def\pyipsii{\pmacro} \def\pcetaiyi{\pmacro} \def\pypsiij{\pmacro} \def\pyipsiONE{\pmacro} \def\ptypsiij{\pmacro} \def\pcyzipsii{\pmacro} \def\pczipsii{\pmacro} \def\pcyizpsii{\pmacro} \def\pcyijzpsii{\pmacro} \def\pcyiONEzpsii{\pmacro} \def\pcypsiz{\pmacro} \def\pccypsiz{\pmacro} \def\pypsiz{\pmacro} \def\pcpsiz{\pmacro} \def\peps{\pmacro} \def\petai{\pmacro} \def\psig{\psi} \def\psigprime{\psig^{\prime}} \def\psigiprime{\psig_i^{\prime}} \def\psigk{\psig^{(k)}} \def\psigki{\psig_i^{(k)}} \def\psigkun{\psig^{(k+1)}} \def\psigkuni{\psig_i^{(k+1)}} \def\psigi{\psig_i} \def\psigil{\psig_{i,\ell}} \def\phig{\phi} \def\phigi{\phig_i} \def\phigil{\phig_{i,\ell}} \def\etagi{\eta_i} \def\IIV{\Omega} \def\thetag{\theta} \def\thetagk{\theta_k} \def\thetagkun{\theta_{k+1}} \def\thetagkunm{\theta_{k-1}} \def\sgk{s_{k}} \def\sgkun{s_{k+1}} \def\yg{y} \def\xg{x} \def\qx{p_x} \def\qy{p_y} \def\qt{p_t} \def\qc{p_c} \def\qu{p_u} \def\qyi{p_{y_i}} \def\qyj{p_{y_j}} \def\qpsi{p_{\psi}} \def\qpsii{p_{\psi_i}} \def\qcpsith{p_{\psi|\theta}} \def\qth{p_{\theta}} \def\qypsi{p_{y,\psi}} \def\qcypsi{p_{y|\psi}} \def\qpsic{p_{\psi,c}} \def\qcpsic{p_{\psi|c}} \def\qypsic{p_{y,\psi,c}} \def\qypsit{p_{y,\psi,t}} \def\qcypsit{p_{y|\psi,t}} \def\qypsiu{p_{y,\psi,u}} \def\qcypsiu{p_{y|\psi,u}} \def\qypsith{p_{y,\psi,\theta}} \def\qypsithcut{p_{y,\psi,\theta,c,u,t}} \def\qypsithc{p_{y,\psi,\theta,c}} \def\qcypsiut{p_{y|\psi,u,t}} \def\qcpsithc{p_{\psi|\theta,c}} \def\qcthy{p_{\theta | y}} \def\qyth{p_{y,\theta}} \def\qcpsiy{p_{\psi|y}} \def\qcpsiiyi{p_{\psi_i|y_i}} \def\qcetaiyi{p_{\eta_i|y_i}} \def\qz{p_z} \def\qw{p_w} \def\qcwz{p_{w|z}} \def\qw{p_w} \def\qcyipsii{p_{y_i|\psi_i}} \def\qyipsii{p_{y_i,\psi_i}} \def\qypsiij{p_{y_{ij}|\psi_{i}}} \def\qyipsi1{p_{y_{i1}|\psi_{i}}} \def\qtypsiij{p_{\transy(y_{ij})|\psi_{i}}} \def\qcyzipsii{p_{z_i,y_i|\psi_i}} \def\qczipsii{p_{z_i|\psi_i}} \def\qcyizpsii{p_{y_i|z_i,\psi_i}} \def\qcyijzpsii{p_{y_{ij}|z_{ij},\psi_i}} \def\qcyi1zpsii{p_{y_{i1}|z_{i1},\psi_i}} \def\qcypsiz{p_{y,\psi|z}} \def\qccypsiz{p_{y|\psi,z}} \def\qypsiz{p_{y,\psi,z}} \def\qcpsiz{p_{\psi|z}} \def\qeps{p_{\teps}} \def\qetai{p_{\eta_i}} \def\neta{n_\eta} \def\ncov{M} \def\npsi{n_\psig} \def\beeta{\eta} \def\logit{\rm logit} \def\transy{u} \def\so{O} \newcommand{\prob}[1]{ \mathbb{P}\left(#1\right)} \newcommand{\probs}[2]{ \mathbb{P}_{#1}\left(#2\right)} \newcommand{\esp}[1]{\mathbb{E}\left(#1\right)} \newcommand{\esps}[2]{\mathbb{E}_{#1}\left(#2\right)} \newcommand{\var}[1]{\mbox{Var}\left(#1\right)} \newcommand{\vars}[2]{\mbox{Var}_{#1}\left(#2\right)} \newcommand{\std}[1]{\mbox{sd}\left(#1\right)} \newcommand{\stds}[2]{\mbox{sd}_{#1}\left(#2\right)} \newcommand{\corr}[1]{\mbox{Corr}\left(#1\right)} \newcommand{\Rset}{\mbox{$\mathbb{R}$}} \newcommand{\Yr}{\mbox{$\mathcal{Y}$}} \newcommand{\teps}{\varepsilon} \newcommand{\like}{\cal L} \newcommand{\logit}{\rm logit} \newcommand{\transy}{u} \newcommand{\repy}{y^{(r)}} \newcommand{\brepy}{\boldsymbol{y}^{(r)}} \newcommand{\vari}[3]{#1_{#2}^{{#3}}} \newcommand{\dA}[2]{\dot{#1}_{#2}(t)} \newcommand{\nitc}{N} \newcommand{\itc}{I} \newcommand{\vl}{V} \newcommand{tstart}{t_{start}} \newcommand{tstop}{t_{stop}} \newcommand{\one}{\mathbb{1}} \newcommand{\hazard}{h} \newcommand{\cumhaz}{H} \newcommand{\std}[1]{\mbox{sd}\left(#1\right)} \newcommand{\eqdef}{\mathop{=}\limits^{\mathrm{def}}} \def\mlxtran{\text{MLXtran}} \def\monolix{\text{Monolix}} $
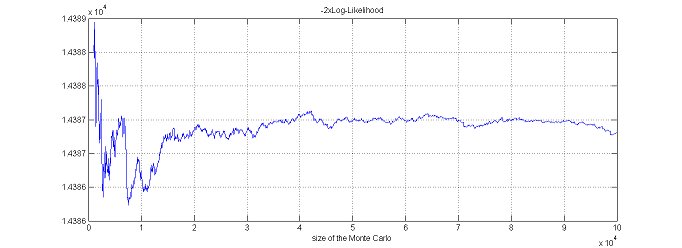
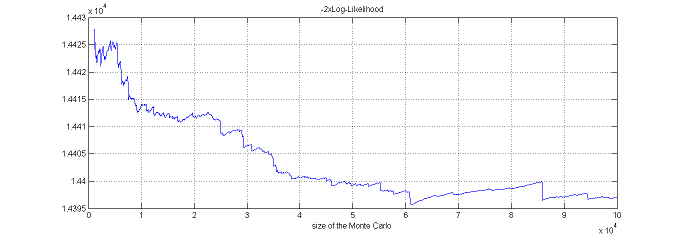
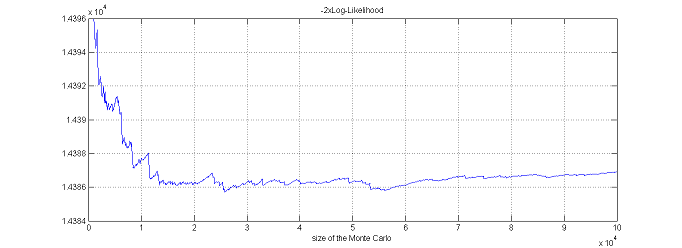
The observed log-likelihood ${\llike}(\theta;\by)=\log({\like}(\theta;\by))$ can be estimated without any approximation of the model using a Monte-Carlo approach.
Since
we will estimate the log-pdf $\log(\pyi(y_i;\theta))$ for each individual and derive an estimate of the log-likelihood as the sum of these individual log-likelihoods. We will explain here how to estimate the log-pdf $\log(\pyi(y_i;\theta))$ for any individual $i$.
Using the $\phi$-representation of the model, notice first that $\pyi(y_i;\theta)$ can be decomposed as follows
$\pyi(y_i;\theta)$ is expressed as a mean. It can therefore be approximated by an empirical mean using a Monte-Carlo procedure:
1. draw $M$ independent realizations $\phi_i^{(1)}$, $\phi_i^{(2)}$,..., $\phi_i^{(M)}$ of the normal distribution $\qphii(\, \cdot \, ; \theta)$,
2. estimate $ \pyi(y_i;\theta)$ with
By construction, this estimator is unbiased: